

在进行文件读写I/O的是,经常遇到一些类似,编码出错的情况,很是烦人。为什么会乱码,就要从编码说起。
1、编码之间的关系
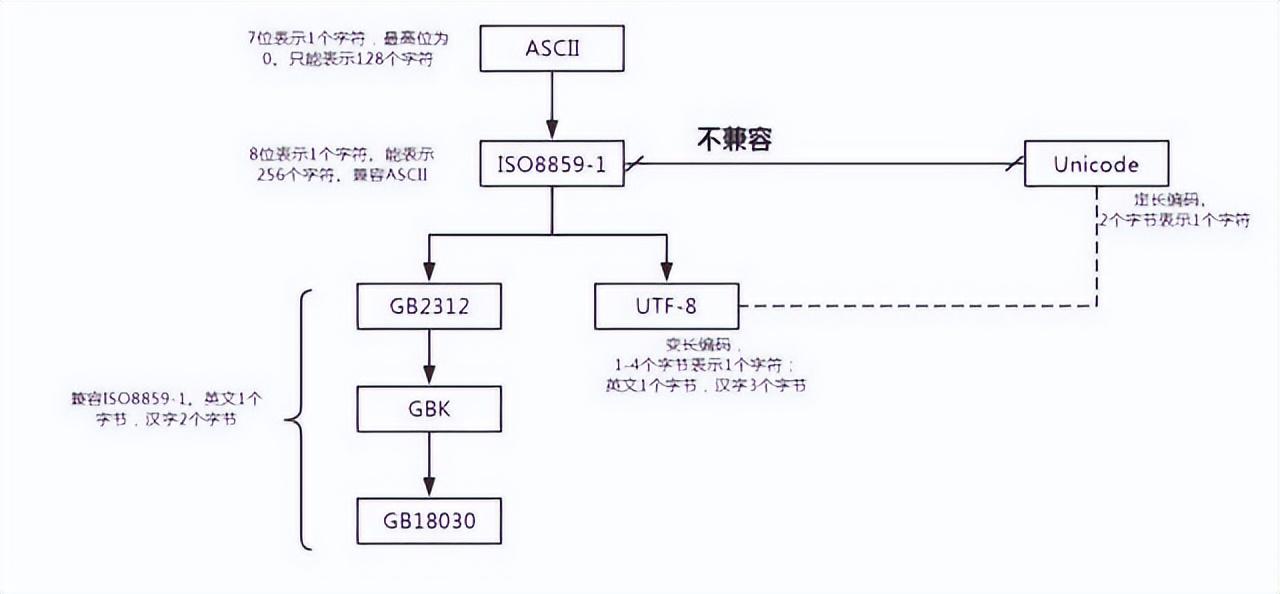
编码关系
图中编码出现的顺序,可以看出编码也是一个逐渐进化与完善的过程;图中从上往下,下面的编码总是能兼容上面的编码;
2、常用编码2.1、ASCII编码
ASCII全称为 Code for ,翻译为“美国信息交换标准代码”。它是世界上最早最通用的单字节编码系统中文文字无线乱码,0,2,2,51 51 51 2 2 2 2,46320,1.36,中文无线乱码(wifi名称乱码方块问号?)-路由网,https://www.luyouwang.net/8048.,主要用来显示现代英语及其他西欧语言,不能表示中文成千上万个的单词。ASCII编码,8bit(一个字节),能表示的最大的整数就是255(2^8-1=255),由于ASCII 的编码最高位总是 0,所以只定义了128 个字符,用0 – 127用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。 还对一些如'n','t','#','@'等字符进行了编码。
2.2、-1编码
ISO-8859-1又称 Latin-1,是一个 8 位单字节字符集,它把 ASCII 的最高位也利用起来,并兼容了 ASCII,新增的空间是 128,但它并没有完全用完。在 ASCII 编码之上又增加了西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号,它是向下兼容 ASCII 编码。
2.3、汉字编码
汉字编码是由我国发布,从到GBK,再到,汉字由少到多,不断补全。GBK全称为 Code ,即汉字内码扩展规范,于 1995 年制定。它主要是扩展了 ,在它的基础上又加了更多的汉字,它一共收录了 21003 个汉字,使用相对较多。
2.4、
通常16bit(2个字节),为了统一所有文字的编码,应运而生,这是一种所有符号的编码,所有的字符都用 16 位(2^16=65536)表示会导致空间的浪费, 在很长的一段时间内都没有得到推广应用。 完全重新设计,不兼容 -1,也不兼容任何其他编码。互联网的诞生,需要传输的数据非常多,如果都是用编码传输会造成很大的浪费。UTF-8,UTF-16,UTF-32就诞生。而且最广泛的就是常用的UTF-8。
娜娜项目网每日更新创业和副业项目
网址:nanaxm.cn 点击前往娜娜项目网
站 长 微 信: nanadh666
2.5、UTF-8
UTF-8, ,可变长度编码,通常使用1~4字节为每个字符编码,兼容ASCII编码,这是一种的一种转换格式。其中,英文字母都是用一个字节表示,而汉字使用三个字节。
在内存中通常以来储存中文文字无线乱码,0,2,2,51 51 51 2 2 2 2,46320,1.36,中文无线乱码(wifi名称乱码方块问号?)-路由网,https://www.luyouwang.net/8048.,保存到文件中就替换为UTF-8等格式,可以压缩空间。从文件中读取的时候,会有个转换编码。就是常用的UTF-8等编码。反之也是,从内存中保存到文件中,就转换为UTF-8等格式。
3、java中编码与字符的关系
java是双字节编码,是utf-16be编码,但是、idea等可以设置默认编码方式。当你的字节序列是某种编码时,这个时候想把字节序列变成字符串,也需要用这种编码方式,否则会出现乱码。
s=”一只青羊”;
byte[] =s.();//这是把字符串转换成字符数组,转换成的字节序列用的是项目默认的编码
for(byte b: )
.out.(.(b & 0xff)+” “);// & 0xff是为了把前面的24个0去掉只留下后八位
//这个函数是把字节(转换成了Int)以16进制的方式显示
str1=new ();//这时会使用项目默认的编码来转换,可能出现乱码
要使用字节序列的编码来进行转换
str2=new (,”utf-16be”);
byte[] =s.(“gbk”);//也可以用指定的编码
4、中文乱码问题
文本文件就是字节序列,可以是任意编码的字节序列,如果我们在中文机器上直接创建文本文件,那么该文件只认识ANSI编码(例如直接在电脑中创建文本文件)。 操作系统默认的编码是 GBK,Linux 操作系统默认的编码是 UTF-8。中文乱码问题只要注意指定编码方式即可规避。
娜娜项目网每日更新创业和副业项目
网址:nanaxm.cn 点击前往娜娜项目网
站 长 微 信: nanadh666