

本文为 AI 研习社编译的技术博客,原标题 :
Why pixel precision is the future of the Image Annotation
作者 |Vahan Petrosyan
翻译 |Yulian 编辑 | Gerald Durrell、邓普斯•杰弗
原文链接:
@vahavp/why-pixel-precision-is-the-future-of-the-image-annotation-12a891367f7b
在这篇文章中,我将分享一些与我在博士研究期间积累的图像注释相关的想法。 具体来说,我将讨论当前最先进的注释方法,它们的趋势和未来方向。 最后,我将简要介绍我们正在构建的注释软件,并对我们的公司进行一些简单叙述。
大纲:
1.图像标注简介

图像注释是选择图像中的对象并按照名称标记它们的过程。 这是人工智能计算机视觉的支柱,例如为了让您的自动驾驶汽车软件准确识别图像中的任何物体,比如行人,需要数十万到数百万注释行人。 其他用例包括无人机/卫星镜头分析,安全和监视,医学成像,电子商务,在线图像/视频分析,AR / VR等。
图像数据和计算机视觉应用的增加需要大量的训练数据。数据准备和工程任务占AI和机器学习项目消耗时间的80%以上。因此,在过去几年中,已经创建了许多数据注释服务和工具来满足该市场的需求。 因此,数据标签在2018年变为15亿美元市场,预计到2023年将增长到50亿。
2.主流注释方法:边界框
最常见的注释技术是边界框,它是在目标对象周围拟合紧密矩形的过程。 这是最常用的注释方法,因为边界框相对简单,许多对象检测算法都是在考虑这种方法的情况下开发的(YOLO,Faster R-CNN等)。 因此,所有注释公司都提供边界框注释(服务或软件)的解决方案。 但是,盒子注释存在主要缺点:
1.一个需要相对较大(通常在100.000s左右)数量的边界框以达到超过95%的检测精度。 例如,对于自动驾驶行业,人们通常会收集数百万个汽车,行人,路灯,车道,视锥等的边界框。
2.无论您使用多少数据,跳动框注释通常不会达到超人检测精度。 这主要是因为盒子区域中包含的物体周围的附加噪声。
3.对于被遮挡的物体图像标注,检测变得极其复杂。在许多情况下,目标物体覆盖的边界框区域不到20%,其余的作为噪声,使检测算法混淆,找到正确的物体(参见示例中的示例,下面的绿框)。
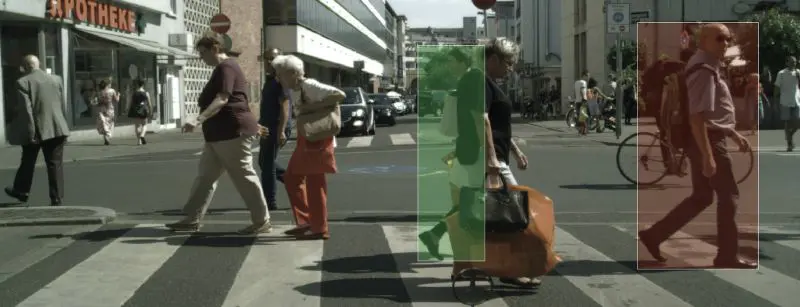
边界框如何失败的示例:绿色框 – 高度遮挡的行人的情况。 红色框 – 高噪声注释
3.图像注释中的像素精度
带有边界框的上述问题可以通过像素精确注释来解决。 然而,这种注释最常用的工具很大程度上依赖于慢速逐点对象选择工具,其中注释器必须穿过对象的边缘。 这不仅非常耗时且昂贵,而且对人为错误非常敏感。 为了进行比较,这样的注释任务通常比边界框注释花费大约10倍。此外,准确地注释相同数量的数据像素可能需要多10倍的时间。因此,边界框仍然是各种应用程序最常用的注释类型。
然而,深度学习算法在过去七年中取得了长足的进步。 虽然在2012年,最先进的算法(Alexnet)只能对图像进行分类,但是当前算法已经可以在像素级别准确识别对象(参见下图)。 对于这种精确的物体检测,像素完美注释是关键。
过去7年深度学习的演变。
3.1. 基于AI /分段的方法
已经存在使用基于分段的解决方案(即,SLIC超像素,基于GrabCut的分割)用于像素化注释的方法。 然而图像标注,这些方法基于像素颜色执行分割,并且在诸如自动驾驶的现实场景中经常表现出差的性能和不令人满意的结果。 因此,它们通常不用于这种注释任务。
在过去的3年中,NVIDIA已经与多伦多大学进行了广泛的研究,以实现像素精确的注释解决方案。 他们的研究主要集中在从给定的边界框生成像素精确多边形,并包括以下论文 -Polygon RNN,Polygon RNN ++,Curve-GCN- 分别于2017年,2018年,2019年在CVPR上发表。 在最好的情况下,使用这些工具生成多边形需要至少两次精确的点击(即生成边界框),并希望它能准确地捕获目标对象。 但是,建议的多边形通常不准确,并且可能比预期花费更多的时间(参见下面的示例)。

封闭对象上的多边形 RNN ++工具示例(视频速度提高2倍)
这种基于多边形的方法的另一个问题是难以选择类似物体的“环状线圈”(拓扑学上),其中需要至少两个多边形来描述这样的对象。
3.2. 一种新的像素化注释方法
像素化注释最简单,最快捷的方法是只需单击一下即可选择对象。 我在瑞典KTH的博士研究期间专门研究了这个问题。 到2018年11月我的博士学位结束时,我们制作了一个简单的工具原型,只需点击一下即可选择对象。 我们的初步实验表明,像素化注释可以加速10-20倍而不会影响选择质量。 以下是它如何在上面显示的相同图像上工作的示例。

SuperAnnotate 的注释(视频速度提高2倍)
与其他AI或基于分段的方法相比,我们还仔细分析了解决方案的优势:
我们的算法速度允许实时分割和注释高达1000万像素的图像
与SLIC超像素不同,我们的分割解决方案可准确生成非均匀区域,用户只需单击一下即可选择大小对象
我们的软件允许我们立即更改段数,从而可以选择最小的对象。
我们的算法的自主学习功能甚至进一步提高了分割的准确性。 即使有几百个注释,也可以观察到分割精度的显着变化。 这进一步加速了注释过程。
与上面讨论的基于Box-to-Polygon的技术相比,我们的软件只需点击一下即可选择环状线圈风格的对象。
最重要的是,随着注释数据量的增加,我们的软件允许自动像素精确注释。
即使与基本边界框注释相比,它需要至少2次精确点击来注释一个对象,我们在该段中只需要1次近似点击,这使得它比生成边界框更快。
通过这种方式,我们将像素注释的成本同时降低到边界框的成本水平,从而允许达到超人精确的检测水平,否则无法通过边界框到达。
此外,由于像素精度不包括噪声,因此与边界框注释相比,需要至少少10倍的数据才能达到一定的准确度。
完成备注
随着我们的软件成为主流(2019年6月推出),我们预计对边界盒的需求最终会消失。 像素精确注释将成为新的标准。
4. 关于 SuperAnnotate
我们是一支由风险投资支持的团队,投资者包括Berkeley Skydeck,即Plug and Play和SmartGateVC–由Tim Draper支持。 我们的团队由来自美国,欧洲和亚洲顶尖大学的博士研究人员组成,他们聚集在一起,提供图像和视频注释领域的新方法,并使“Human in the loop”任务的效率在更准确水平上提高到了100倍。
娜娜项目网每日更新创业和副业教程
网址:nanaxm.cn 点击前往娜娜项目网
站 长 微 信: nanadh666