


小兵先说:以下这篇文章最早的出处是沈浩老师博客原创,由 计量经济学 公众号整合转载发布在公众号平台,该文中图片右下角印有“计量经济学”,但我要强调一下原创归沈浩老师,如有其它账号转载请注明原创来源。
由于原文很长,且为多篇博文合并整理,为了方便阅读,下面的图文由数据小兵进行重新分段规划、编写排版,本文标题也由小兵拟定,如有不妥还请及时告知。
==全文如下==
关于时间序列,有好多软件可以支持分析,大家比较熟悉的可能是EVIEWS、SPSS、还有STATA,具体用啥软件,结果都是一样的,但是SPSS作为一款学习简单,使用容易的软件还是值得大家关注的。
01
预测是对尚未发生或目前还不明确的事物进行预先的估计和推测时间序列模型有哪些,是在现时对事物将要发生的结果进行探讨和研究,简单地说就是指从已知事件测定未知事件。
为什么要预测呢,因为预测可以帮助了解事物发展的未来状况后,人们可以在目前为它的到来做好准备,通过预测可以了解目前的决策所可能带来的后果,并通过对后果的分析来确定目前的决策,力争使目前的决策获得最佳的未来结果。
我们进行预测的总的原则是:认识事物的发展变化规律,利用规律的必然性,是进行科学预测所应遵循的总的原则。
这个总原则实际上就是事物发展的。
1-“惯性”原则——事物变化发展的延续性;
2-“类推”原则——事物发展的类似性;
3-“相关”原则——事物的变化发展是相互联系的;
4-“概率”原则——事物发展的推断预测结果能以较大概率出现,则结果成立、可用;
02
时间序列预测
时间序列预测主要包括三种基本方法:
1-内生时间序列预测技术;
2-外生时间序列预测技术;
3-主观时间序列预测技术;
当然今天我们主要讨论内生时间序列预测技术——也就是只关注时间序列的下的预测问题!
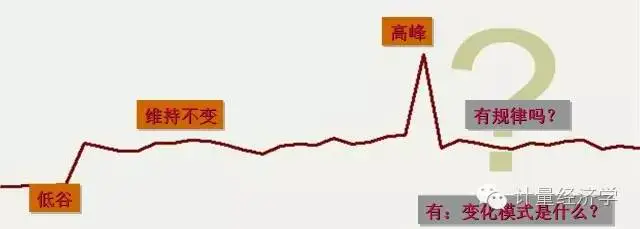
从数据分析的角度来考虑,我们需要研究:
时间序列有一明显的特性就是记忆性(memory),记忆性系指时间数列中的任一观测值的表现皆受到过去观测值影响。
时间序列主要考虑的因素是:
长期趋势(Long-term trend)
时间序列可能相当稳定或随时间呈现某种趋势。时间序列趋势一般为线性的,二次方程式的或指数函数(exponential 。
季节性变动(Seasonal variation)
按时间变动,呈现重复性行为的序列。季节性变动通常和日期或气候有关。季节性变动通常和年周期有关。
周期性变动(Cyclical variation)
相对于季节性变动,时间序列可能经历“周期性变动”。周期性变动通常是因为经济变动。
随机影响(Random effects)
03
时间序列预测技术
预测技术主要包括两大类:
第一:指数平滑方法
描述时间序列数据的变化规律和行为,不去试图解释和理解这种变化的原因。
例如:您可能发现在过去的一年里,三月和九月都会出现销售的高峰,您可能希望继续保持这样,尽管您不知道为什么。
第二:ARIMA模型
描述时间序列数据的变化规律和行为,它允许模型中包含趋势变动、季节变动、循环变动和随机波动等综合因素影响。
具有较高的预测精度,可以把握过去数据变动模式,有助于解释预测变动规律,回答为什么这样。
下面看看如何采用SPSS软件进行时间序列的预测!
04
案例数据预分析
这里我用PASW Statistics 18软件,大家可能觉得没见过这个软件时间序列模型有哪些,其实就是SPSS18.0,不过现在SPSS已经把产品名称改称为PASW了!博易智讯的马博士刚刚把这个产品测试版给我,还是中文版,先睹为快吧!
我们通过案例来说明:(本案例并不想细致解释预测模型的预测的假设检验问题,1-太复杂、2-相信软件)
假设我们拿到一个时间序列数据集:某男装生产线销售额。一个产品分类销售公司会根据过去10年的销售数据来预测其男装生产线的月销售情况。
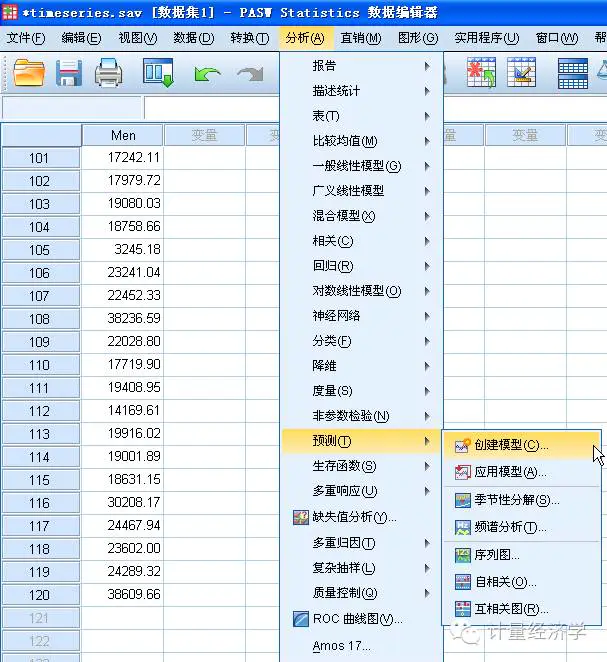
现在我们得到了10年120个历史销售数据,理论上讲,历史数据越多预测越稳定,一般也要24个历史数据才行!
大家看到,原则上讲数据中没有时间变量,实际上也不需要时间变量,但你必须知道时间的起点和时间间隔。
当我们现在预测方法创建模型时,记住:一定要先定义数据的时间序列和标记!
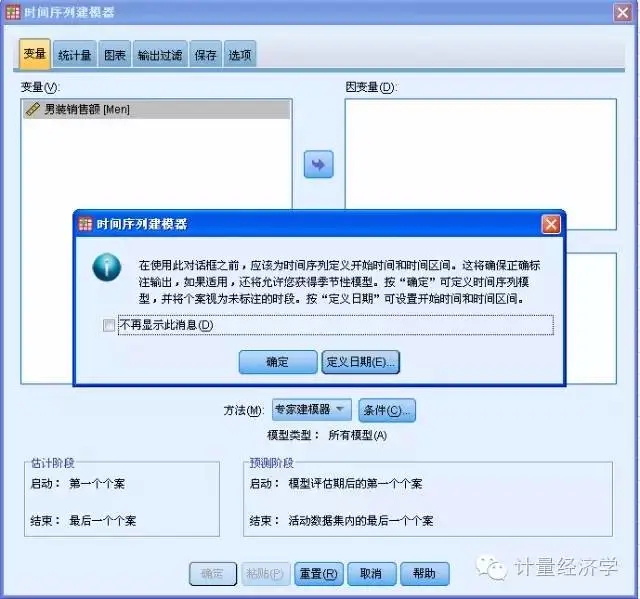
这时候你要决定你的时间序列数据的开始时间,时间间隔,周期!在我们这个案例中,你要决定季度是否是你考虑周期性或季节性的影响因素,软件能够侦测到你的数据的季节性变化因子。
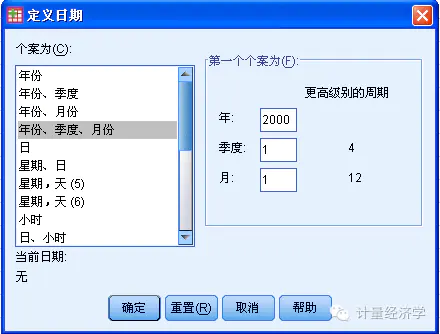
定义了时间序列的时间标记后,数据集自动生成四个新的变量:YEAR、QUARTER、MONTH和DATE(时间标签)。
接下来:为了帮我们找到适当的模型,最好先绘制时间序列。时间序列的可视化检查通常可以很好地指导并帮助我们进行选择。
另外,我们需要弄清以下几点:
这时候我们就可以看到时间序列图了!
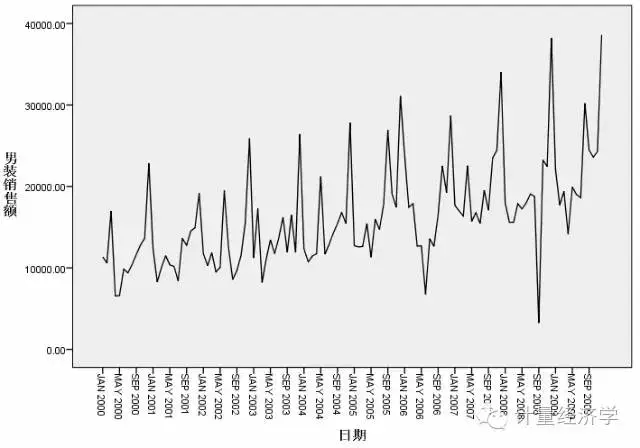
我们看到:此序列显示整体上升趋势,即序列值随时间而增加。上升趋势似乎将持续,即为线性趋势。
此序列还有一个明显的季节特征,即年度高点在十二月。季节变化显示随上升序列而增长的趋势,表明是乘法季节模型而不是加法季节模型。
此时,我们对时间序列的特征有了大致的了解,便可以开始尝试构建预测模型。时间序列预测模型的建立是一个不断尝试和选择的过程。
PASW Statistics提供了三大类预测方法:
1-专家建模器,
2-指数平滑法,
3-ARIMA

指数平滑法
指数平滑法有助于预测存在趋势和/或季节的序列,此处数据同时体现上述两种特征。创建最适当的指数平滑模型包括确定模型类型(此模型是否需要包含趋势和/或季节),然后获取最适合选定模型的参数。
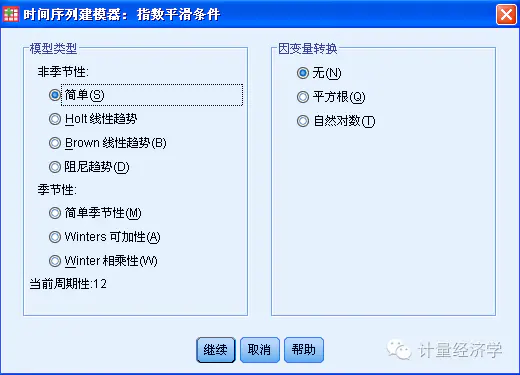
05 案例示范
1-简单模型预测
(即无趋势也无季节)
娜娜项目网每日更新创业和副业项目
网址:nanaxm.cn 点击前往娜娜项目网
站 长 微 信: nanadh666
首先我们采用最为简单的建模方法,就是简单模型,这里我们不断尝试的目的是让大家熟悉各种预测模型,了解模型在什么时候不适合数据,这是成功构建模型的基本技巧。我们先不讨论模型的检验,只是直观的看一下预测模型的拟合情况,最后我们确定了预测模型后我们再讨论检验和预测值。
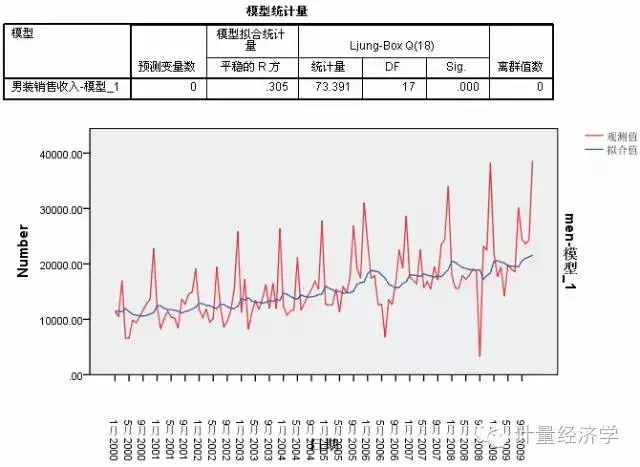
从图中我们看到,虽然简单模型确实显示了渐进的上升趋势,但并不是我们期望的结果,既没有考虑季节性变化,也没有周期性呈现,直观的讲基本上与线性预测没有差异。所以我们拒绝此模型。
05 案例示范
2-Holt线性趋势预测
Holt线性指数平滑法,一般选择:针对等级的平滑系数lapha=0.1,针对趋势的平滑系数gamma=0.2;
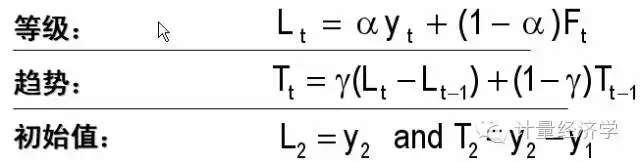
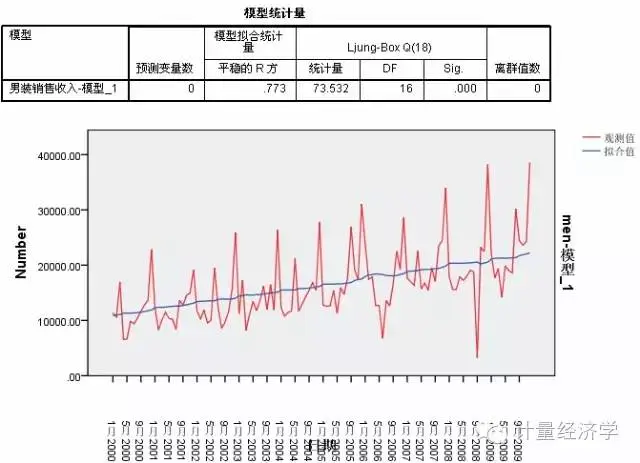
从上面的拟合情况看,Holt预测模型更平滑了,也就是说Holt模型比简单模型显现了更强的平滑趋势,但未考虑季节因素,还是不理想,所以还应放弃此模型。
05 案例示范
3-简单季节性模型
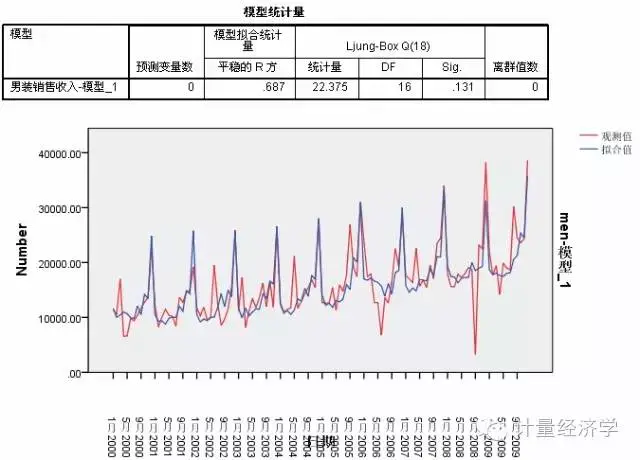
当我们考虑了季节性变化后,简单季节性预测模型基本上较好的拟合了数据的大趋势,也就是考虑了趋势和季节。
05 案例示范
4-Winters相乘法预测模型
我们再次选择Winters预测模型,实际上这时候非统计专业人士其实已经可以不用考虑Winters模型的原理了,因为对于大部分经营分析人员,如果期望把每一个预测方式的细节都搞清楚,并不容易,也容易陷入数量层面的纠葛中,我们只要相信软件算法就可以了。
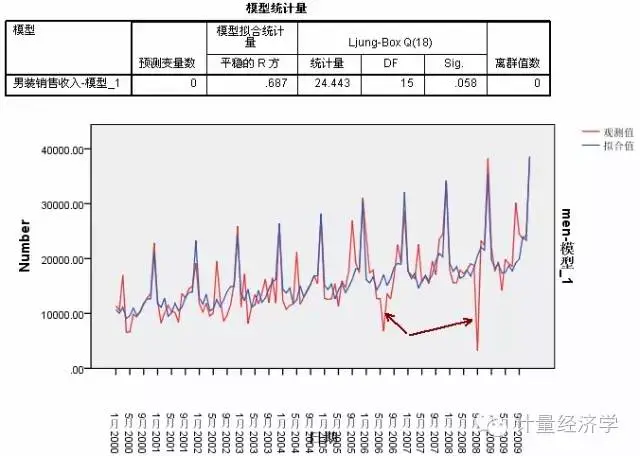
此时,在数据集的时间跨度为10年,并且包含 10 个季节峰值(出现在每年十二月份)中,简单季节模型和Winters模型都扑捉到了这10个峰值与实际数据中的10个年度峰值完全匹配的预测结果。此时,我们基本上可以得到了一个比较满意的预测结果。
此时也说明,无论采用指数平滑的什么模型,只要考虑了季节因素,都可以得到较好结果,不同的季节性指数平滑方法只是细微差异了。
但是,我们仔细看预测值和拟合值,还是有一些上升和下降的趋势和结构没有扑捉到。预测还有改进的需求!
05 案例示范
5-ARIMA预测模型
ARIMA 模型是自回归AR和移动平均MA加上差分考虑,但ARIMA模型就比较复杂了,对大部分经营分析人员来讲,要搞清楚原理和方程公式,太困难了!期望搞清楚的人必须学过随机过程,什么平稳过程、白噪声等,大部分人头都大了,现在有了软件就不问为什么了,只要知道什么数据In,什么结果Out,就可以了。

我们采用专家建模器,但指定仅限ARIMA模型,并考虑季节性因素。
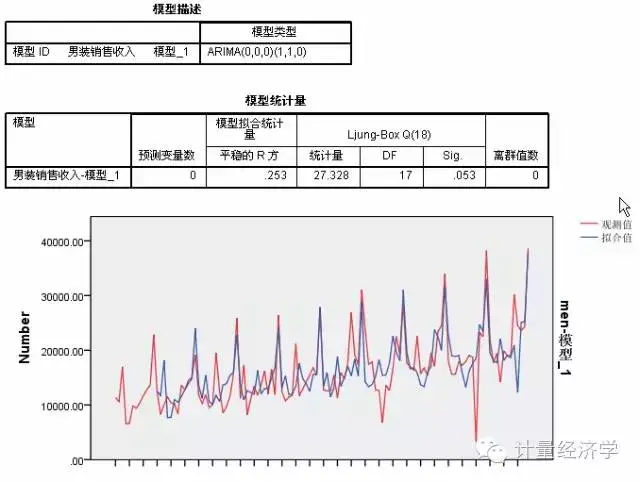
此时,我们看到模型拟合并相比较简单季节性和Winters模型没有太大的优势,结果可接受,但是大家注意到没有,实际上我们一直没有考虑自变量的进入问题,假如我们有其它变量可能会影响到男装销售收入,情况又会发生什么变化呢?
发现大家都对预测问题非常关注,尤其是数据挖掘领域,有时候分类问题与预测问题在表达上区分不开,有时候分类就是预测,比如通过判别分析、C5.0规则或Logistics回归进行监督类建模,得到的结论说该客户是什么类别等级,似乎也可以说是预测;
当然,如果能够预测该消费者什么时候流失,也就是进行了分类;这样说吧,其实有时候并不需要严格区分分类和预测,关键是时间点。从这也可以看出,预测问题内涵和外延是非常宽泛的,但研究者心中要有数,这决定了你得到的结果该如何应用。
前面的博文提到,如果我们考虑时间序列预测包含有预测和干扰变量如何解决的问题。
从方法角度讲:
过去没有统计分析软件要完成预测可以说是困难的,现在有了软件工具就方便多了。
从技术角度讲:
预测模型如果能够排除因为异常原因造成的时间点事件和时间段时间,就好了。例如某天停电没有开业,或者某一段时间比如发生甲型H1NI一周没有营业收入,这些事件必须能够告诉模型未来不会再发生了;
当然,我们也要把未来会重复发生的干扰因素纳入模型,例如:我们学校某天要开运动会,小卖部的可乐销量一定提高,或者我们学校7-8月份放暑假,销量一定减少,像这样的时间点和时间段事件未来会重复出现,我们如果能够告诉模型,那么预测会更准确。
当然如果我们建立的模型能够预测未来,并能够将未来可预见的事件,包括时间点和时间段干扰纳入预测是非常好的事情啦!
甚至,我们应该能够把预测模型中的,预测未来周期内的不可预见的时间点和时间段随时干预预测结果,这就需要考虑如何将预测模型导入生产经营分析系统了。
下面的数据延续前两篇的案例,只是增加了自变量,(因为手头这个案例没有干预因素变量)
在我们增加了5个自变量后,采用预测建模方法,选择专家建模器,但限制只在ARIMA模型中选择。
确定后,得到分析结果,我们现在来看一下与原来的模型有什么不同。
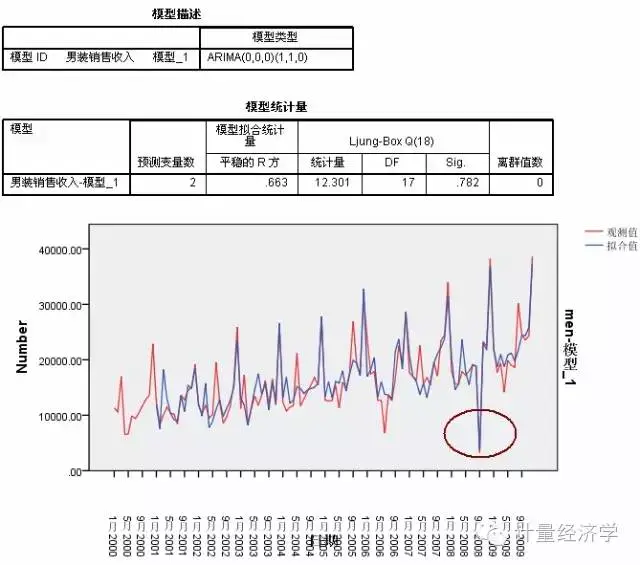
从预测值看,比前一模型有了改进,至少这时候的模型捕捉了历史数据中的下降峰值,这可以认为是当前比较适合的拟合值了。
如果我们观察预测结果,可以发现模型选择了两个预测变量。
注意:使用专家建模器时,只有在自变量与因变量之间具有统计显著性关系时才会包括自变量。如果选择ARIMA模型,“变量”选项卡上指定的所有自变量(预测变量)都包括在该模型中,这点与使用专家建模器相反;
当确定了最终选择的预测模型和方法后,我们就可以预测未来了,当然你要指定预测未来的时间点,这里我们时间包括年、季度和月份;假定我们预测未来半年的销售收入。
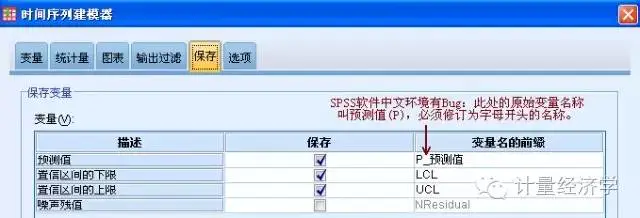
我们分别设定:预测值输出,95%置信度的上下限。注意:SPSS中文环境有个小Bug,必须改一下名字!
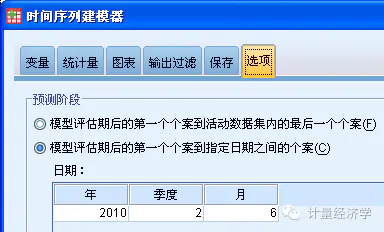
在选项中,选择你的预测时间,预测期将根据你事先定义的数据时间格式填写。(后面的模型为了让大家看清楚,实际上我预测了一年的数据,也就是2010年的4个季度的12个月)。
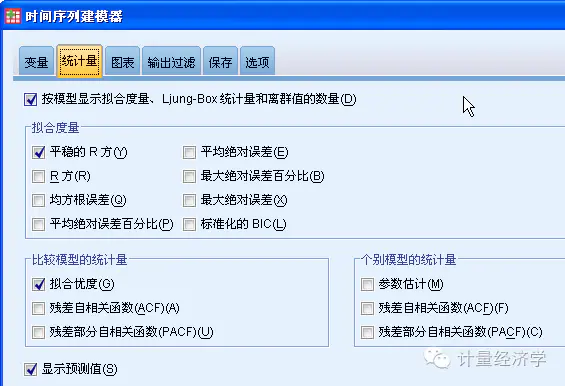
自变量的选择问题,在预测未来半年的销售收入中,ARIMA模型可以把其它预测变量纳入考虑,但如何确定未来这些预测变量的值呢?
主要方法可以考虑:1)选择最末期数据;2)选择近三期数据的平均;3)选择近三期的移动平均
这里我们选近三期移动平均作为预测自变量数值。
上面就是预测结果!于此同时,SPSS活动数据集中也存储了预测值!
最后,我们要解决时间序列预测的检验和统计问题!
说实在话,我比较关注偏好商业应用,就是看得见就做得到!从上面的分析,我们基本上就知道了哪种预测模型更好,也就不去较真只有专业统计学者才关心的统计和检验问题,把这些交给统计专家或学术研究吧!(如果你是写学术论文,就必须强调这一点了!)
实际上我们可以通过软件得到各种统计检验指标和统计检验图表!
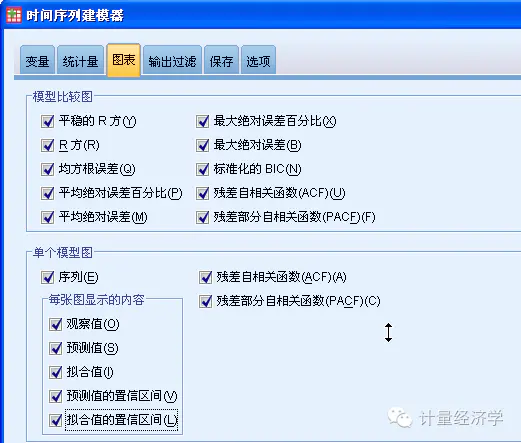
最后我们看一眼统计检验指标结果:
大家可以把我们前面做的结果进行相互比较,或许你能够看出哪些指标更好,哪些指标该如何评测了!
我看出来了,比如:Sig值越大越好,平稳得R方也是越大越好吧!
Sig.列给出了 Ljung-Box 统计量的显著性值,该检验是对模型中残差错误的随机检验;表示指定的模型是否正确。显著性值小于0.05 表示残差误差不是随机的,则意味着所观测的序列中存在模型无法解释的结构。
平稳的R方:显示固定的R平方值。此统计量是序列中由模型解释的总变异所占比例的估计值。该值越高(最大值为 1.0),则模型拟合会越好。
检查模型残差的自相关函数 (ACF) 和偏自相关函数 (PACF) 的值比只查看拟合优度统计量能更多地从量化角度来了解模型。合理指定的时间模型将捕获所有非随机的变异,其中包括季节性、趋势、循环周期以及其他重要的因素。如果是这种情况,则任何误差都不会随着时间的推移与其自身相关联(自关联)。这两个自相关函数中的显著结构都可以表明基础模型不完整。
如果你一定要理解RMSE或者MAE等统计检验量,只好找来教科书好好学习了!我想,等我要写教科书的时候,一定会告诉大家如何检验这些统计量,并给出各种计算公式!但我的学生或读者大部分是文科或企业经营分析人员,讲这些东西他们都会跑了!
大家不要忘了,SPSS时间序列预测模块还包含模型应用,也就是可以把预测模型转存为XML模型文件,以后预测的时候就可以不用原始数据了!
==全文完==
数据小兵坚持写博客已经12年
坚持写微信公号文章6年
坚持更新SPSS视频课程2年
坚持一对一答疑讨论2年
绝对超值:一对一答疑
欢迎加入SPSS视频课程
竭诚服务
娜娜项目网每日更新创业和副业项目
网址:nanaxm.cn 点击前往娜娜项目网
站 长 微 信: nanadh666