

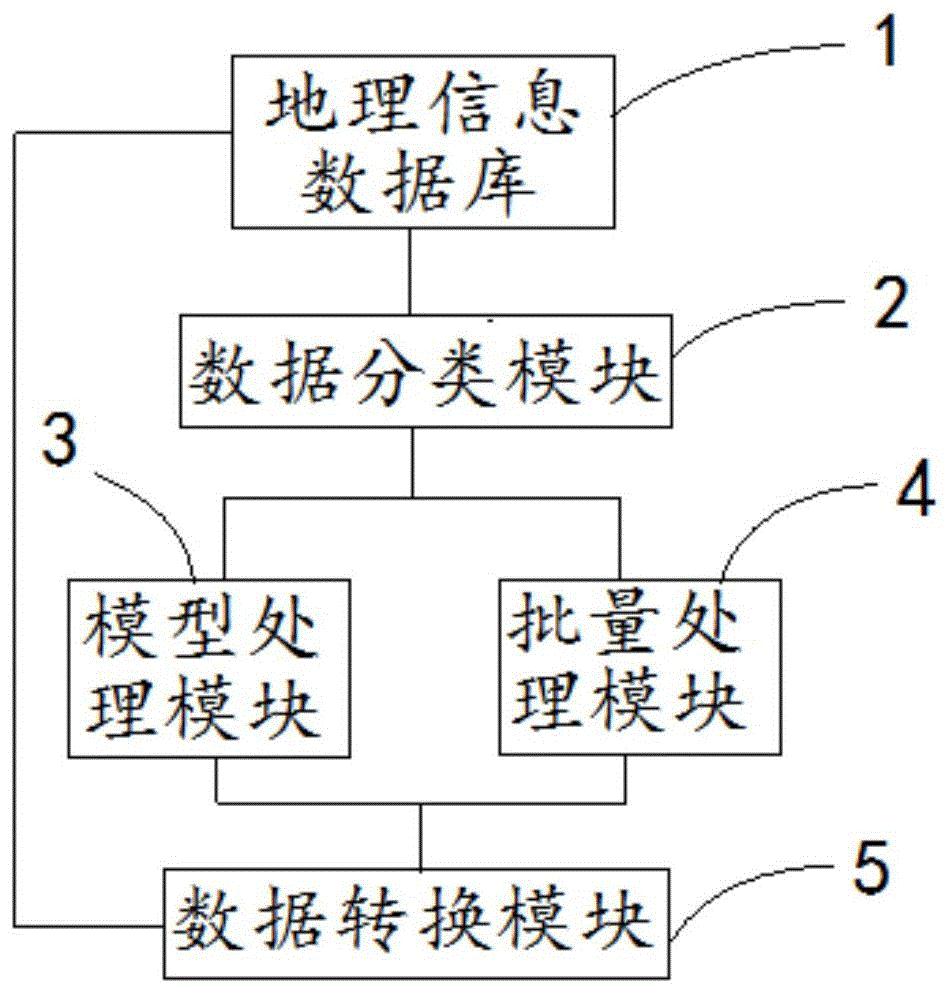
“基于当前大模型企业的数据训练和数据消化能力,在穷尽其本身能力所能获取的人类生产的数据后,可能到2025年这些企业就将面临无人类生成数据可用的问题。”熊辉表示。
而这或许也是OpenAI急于将网页爬虫公开化的原因。其官方发布的论文显示,早在GPT-3.0训练所使用的753GB数据中,除21GB书籍数据与101GB期刊数据,其余数据来源中11.4GB的维基百科数据、50GB的Reddit(海外社交平台)连接数据与570GB的Common Crawl(免费网页数据库,主要内容来源于网页爬虫)都与网页相关,而书籍与期刊的数据库存与增长有限,未来网页数据在大模型训练数据集中所占比重或将进一步提升。
但网页数据存在的问题也非常明显,作为相对公开的数据来源,虽然其在可获得性与数量方面较为理想,但网页本身的内容质量却良莠不齐,且随着人工智能在C端的大规模应用,越来越多本就是AI生成的文本、图片、视频也更加容易导致“递归的诅咒。”
熊辉指出,大模型使用AI生成的数据而可能产生的崩溃或偏见,本质上来源于其训练中的自我增强循环,即模型训练发生了样本偏移或训练分布偏移,陷入到一种错误或有限的思维定势中,形成局部的信息茧房现象。在人工智能训练数据来源方面,数据隐私和数据层面的缺陷导致的偏见与伦理问题,也是当前产业面临的主要问题。
他进一步表示,要避免因数据问题而导致的模型崩溃或偏见,通常最普遍的做法时引入多元的训练数据,即便是同一类型的数据,不同的数据来源也将一定程度上避免数据使用陷入自我增强循环,同时辅助以对抗生成等技术来判断数据质量。
爬虫争议
但作为一种大规模的网页信息爬取工具,爬虫在互联网产业中的使用往往伴随着巨大争议,网站所有者认为其攫取了自身的平台价值,在网站上发布内容的用户则面临版权与个人隐私权益被侵害的风险。
娜娜项目网每日更新创业和副业项目
网址:nanaxm.cn 点击前往娜娜项目网
站 长 微 信: nanadh666
在美国最为知名的爬虫软件案件之一发生在微软旗下职业社交平台LinkedIn与数据分心公司HiQ之间,后者通过爬取前者数据并进行处理后将分析结果出售给相关企业获利,双方关于第三方是否有权爬取网站信息展开长达五年的诉讼拉锯。最终,该案以法院裁定HiQ违反LinkedIn用户协议,赔偿50万美元并禁止其未经同意自动化访问复制数据告终。
今年4月,作为OpenAI ChatGPT、谷歌Bard等多个公司大语言模型的重要数据来源,美国社交媒体平台Reddit宣布将向访问其应用程序编程接口的公司收费,不再免费为科技巨头提供免费的数据内容。随后,Twitter(现名X)CEO马斯克亦公开指责微软非法使用Twitter数据训练AI模型,并声称将就此起诉微软。
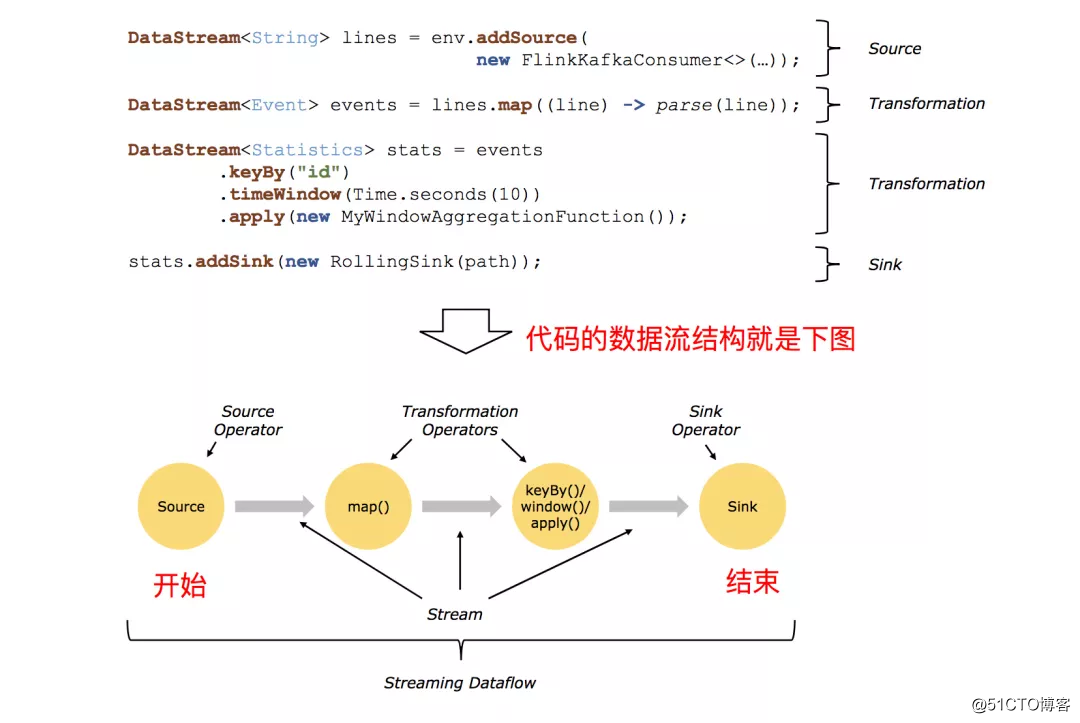
为应对可能的合规争议,OpenAI在发布GPTBot时也为网站所有者提供了屏蔽爬虫的方法——只要在网站的robots.txt(爬虫协议)中添加对应代码,即可禁止或允许GPTBot访问爬取部分网站内容。
但这种把球踢给网站所有者的做法也并不能完全避免合规风险。一个最为突出的问题是,网站只是网络信息的展示平台,网站所有者并不天然具有其他网民发布在网站上信息内容的所有权,即便爬虫方取得网站所有者同意,其爬取网站信息的行为依然可能触犯内容发布者的版权权益。
王新锐表示,相关信息的安全程度将取决于OpenAI是否将对相关信息采取有效的安全技术保障措施,如加密等,但这也并不能完全排除过滤后数据爬取仍可能获取一定个人可识别信息的可能性。
近年来,各国也在不断加强与细化人工智能训练数据的合规要求。例如我国最新发布的《生成式人工智能服务管理暂行办法》中也明确提出“生成式人工智能服务提供者应依法开展预训练、优化训练等训练数据处理活动,包括使用具有合法来源的数据和基础模型;涉及知识产权的,不得侵害他人依法享有的知识产权”等要求。
除版权问题外,个人隐私同样是网页爬虫在获取数据时难以避免的敏感问题,虽然OpenAI承诺GPTBot爬取的网页将被过滤筛选以“去除已知包含个人信息的来源”,以试图从网站类型与源头控制对个人可识别信息的收集,但在具体实践中技术的有效程度仍有待检验。
王新锐表示,相关信息的安全程度将取决于OpenAI是否将对相关信息采取有效的安全技术保障措施,如加密等,但这也并不能完全排除过滤后爬虫仍可能获取一定个人可识别信息的可能性。
应对数据困局
正如前文所言,作为近年乘AI热潮兴起而崭露头角的新兴公司,数据积累将成为OpenAI在未来产业竞争中重要的短板,而在进一步获取数据的过程中,来源与流程合规以及愈加严格的监管也将成为其不得不面临的两难。
在这样的背景下,效仿其他的互联网平台的合规举措,在法规与行业框架的模糊地带尽可能拓展数据来源,成为包括OpenAI在内大多数人工智能开发者的选择。
例如,提供给网站所有者爬虫屏蔽方式的举措,也是承袭自其他互联网公司的既有做法。在谷歌官网,同样对其使用的一系列爬虫程序和用户代理字符串也均进行了公示说明,明确网站所有者可以通过将Googlebot, Googlebot Image, Googlebot News等爬虫程序添加到站点robots. txt中来禁止其访问网站。
但正如此前OpenAI已陷入艺术家与作家就版权问题对其发起的诉讼,相同的做法无论在美国或是其他国家,都面临着不容忽视的合规问题。
王新锐表示,相较而言,我国的法律法规显然对数据爬取采取了更严格的监管路径。在我国数据爬取受到多部法律法规的监管,一旦超过合法收集、利用的限度,数据爬取将存在侵犯个人信息权益、侵犯知识产权、不正当竞争以及危害计算机信息系统类的违法甚至犯罪风险,需承担相应民事、行政乃至刑事责任。
而随着数据资源枯竭的危机一步步逼近,方兴未艾的人工智能产业在加足马力发展的同时,又该如何应对模型“养料”供应不足这一现实问题?
熊辉指出,在产业发展初期,各大公司肯定会穷尽一切可能的方法获取其能够接触的所有数据,早期的数据获取方式在市场驱动下必然是粗犷式的;而随着数据资源逐渐耗尽,下一步企业的数据利用也会在管理驱动下更为精细化数据质量控制,例如做更为细致的数据标注与清洗;在此之后,如果想进一步挖掘数据价值,则有赖于进一步创新,其中包括数据来源与数据利用方式的创新,例如通过拆解流程、划分步骤的方式,丰富数据内容的维度。
“打个比方,对于一年级还未接触复杂乘除计算的小朋友,51÷3的数学问题比较复杂网页无法访问,但是将其拆解为(30+21)÷3后,就可以将其分为30÷3与21÷3两个九九乘法表可以解决的简单问题,与纯粹由AI生成的数据不同,这一基于人类生成数据拆解所产生的步骤数据,在AI训练中也是有价值的。”熊辉表示,通过人工或AI辅助,数据资源的进一步开发与挖掘将是缓解数据枯竭问题的主要途径。
近日,继日本画师、好莱坞从业者等群体后网页无法访问,多家海外媒体机构也加入呼吁保护生成式人工智能训练数据版权的行列中。在法新社、欧洲新闻图片社等媒体签署的一封公开信中,其督促全球立法者考虑制定法规,增强人工智能训练数据来源透明度,并在获取数据前征求权利人同意。
随着AI产业的进一步发展及各行业和群体对数据价值与权利意识的觉醒,如何构建数据生产方、持有方与数据使用方之间的权利义务关系,成为从监管到每一个互联网参与者都需要面对的现实问题。
娜娜项目网每日更新创业和副业项目
网址:nanaxm.cn 点击前往娜娜项目网
站 长 微 信: nanadh666